前言:一筆訂單被做兩次,不是浪費,是賠錢
身為菜機的我,沒什麼錢賠,所以要戰戰兢兢,如履薄冰
我手上有個製造業的排程流程,大概長這樣:
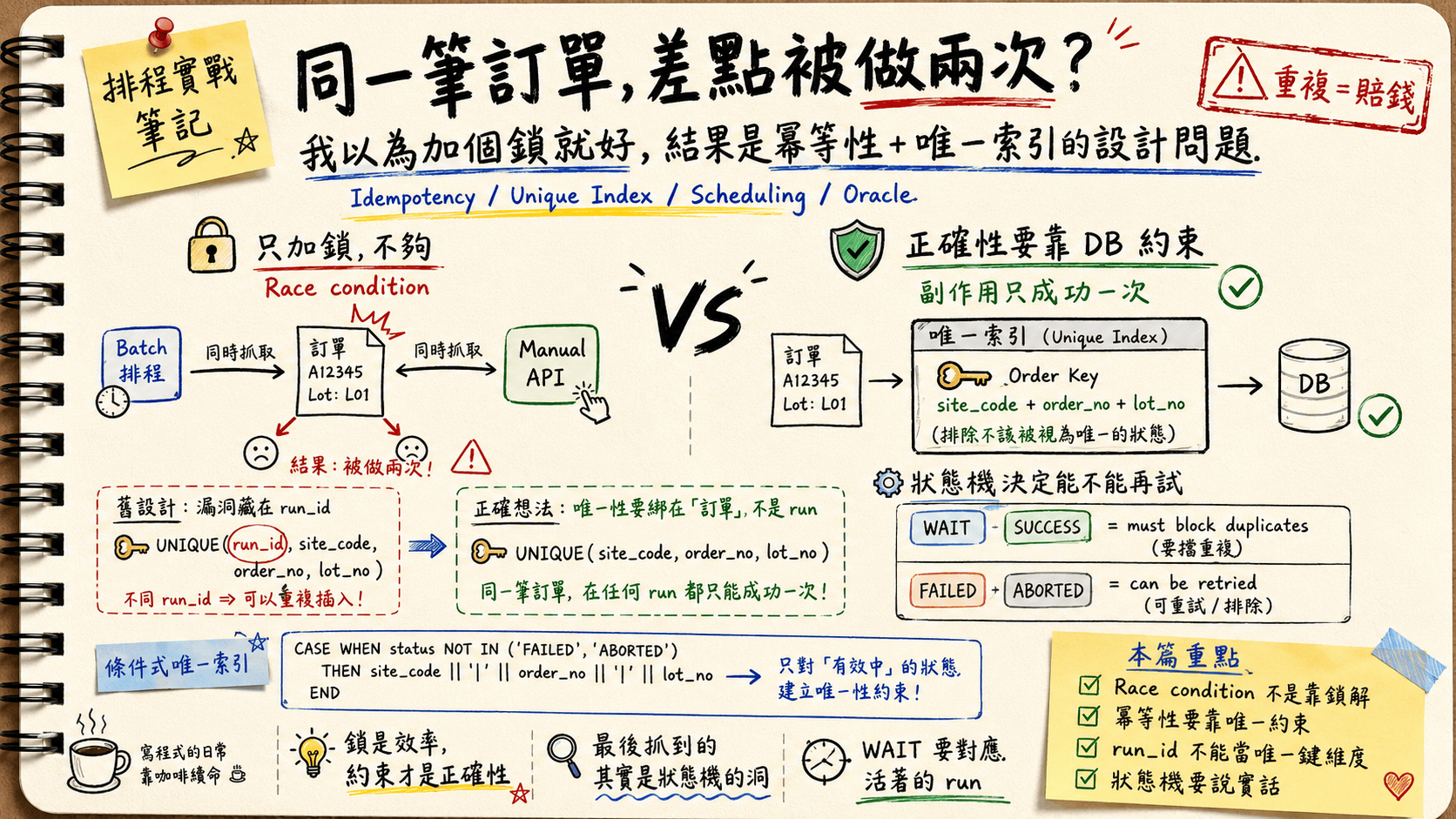
同一筆訂單被做兩次,不是浪費,是賠錢:批次與人工 API 幾乎同時撈到同一筆還是 N 的訂單,各自處理、各自改成 Y——這篇要解的不是效能問題,是正確性問題。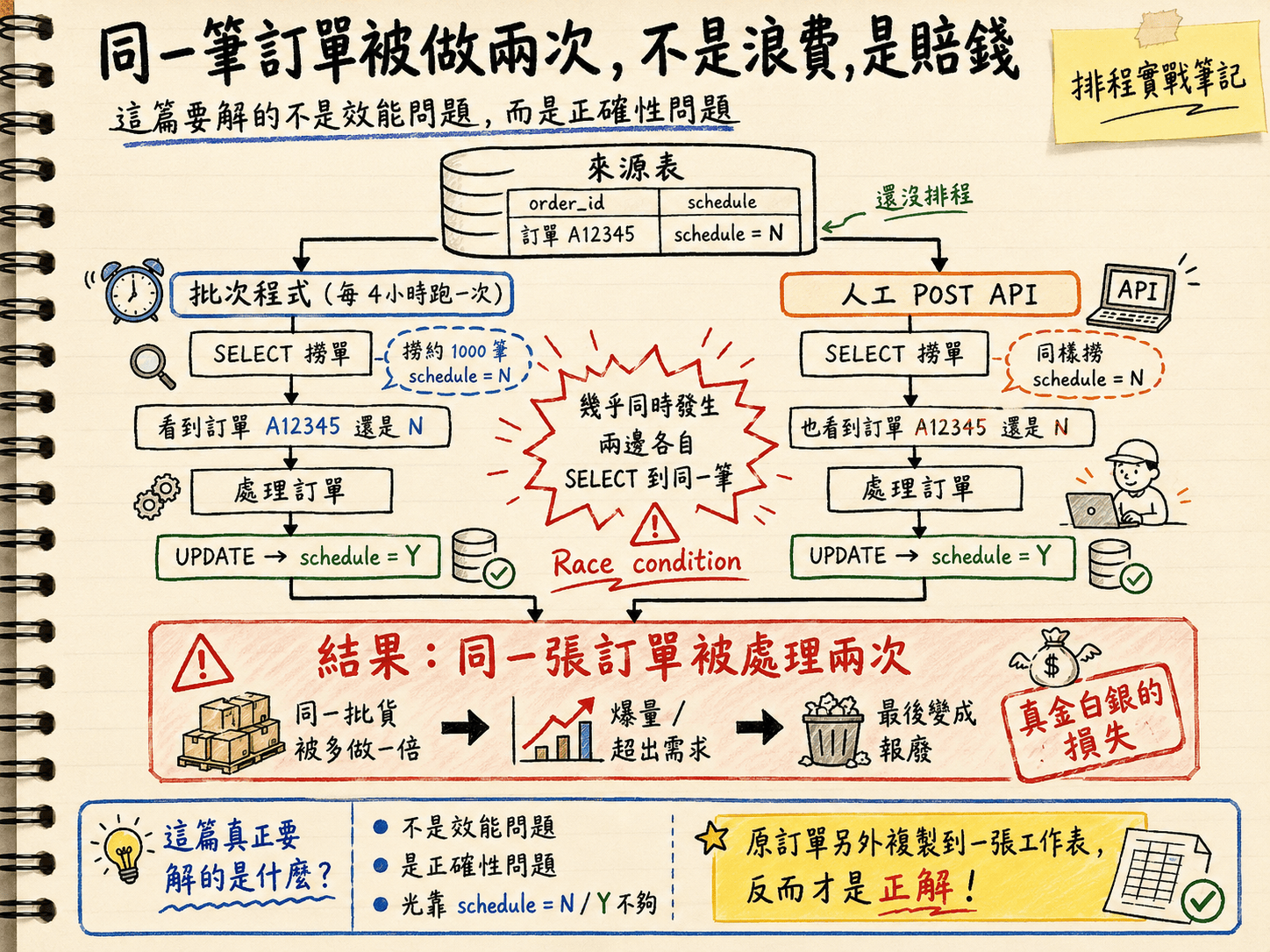
schedule = N),一筆一筆處理,處理完就把那筆的 flag 改成 schedule = Y。同時,用戶也能透過一支人工 POST API 觸發——同樣是撈出還是 N 的訂單、處理、改成 Y。
今天我要新增一隻人工排程 API,如果批次跟人工同時跑起來:兩邊各自 SELECT 到同一筆還是 N 的訂單,就會發生同一筆訂單被處理兩次,因為兩邊都覺得「這筆還沒人做,我來做」,各自處理、各自把它改成 Y。
結果就是——同一張訂單被處理了兩次。 GG!!
如果這是個發優惠券的系統,頂多多送一張就算了。但這是製造排程。同一張訂單投兩次,等於同一批貨被多做了一倍:爆量、超出需求、最後變成報廢。這不是浪費一點運算資源的等級,是真金白銀的損失。
所以這篇要解的不是「效能」問題,是「正確性」問題,而我一開始完全低估它了。還想說,同事為什麼要設計那麼複雜,還把原訂單多拷貝一份出來,另外存到一張 Table,結果發現那才是正解!
第零層:我以為原作者在找麻煩
接手這個流程的第一天,我先卡在一個設計上。
訂單明明在來源表就有了,但這套系統還另外把它複製進一張獨立的工作項目表 schedule_item,而且這張表有自己的一套狀態欄位(WAIT / SUCCESS / FAILED / ABORTED)。我第一個反應很直覺:
原作者是不是在找麻煩?原表就有
N/Yflag 不就解決了,幹嘛還多開一張表、還搞一堆狀態?這不是違反 single source of truth 嗎?
後來我才發現,那張我嫌多餘的表,正是整件事「不出錯」的地基。而我會這樣想,是因為我把 SSOT 的意思搞錯了。
SSOT 講的是「每個『事實』只有一個權威來源」,不是「表越少越好」。 我把「單一真理」理解成「合併成一張表」,但這裡其實有兩個不同的事實:
- 「這張訂單的業務資料是什麼」 → 它的家是來源表。
- 「這張訂單被排程/處理的狀態是什麼」 → 它的家是
schedule_item表。
這是兩件事,各自有一個家,SSOT 不但沒被違反,反而能正確反應資料狀態。真正違反 SSOT 的,是「把處理狀態硬塞回來源表那個 N/Y flag」——那是逼一個欄位同時背「業務資料」跟「處理進度」兩種語意。
而且更關鍵的是:後面整套解法的命脈——唯一約束——一定要掛在「記錄處理這個動作」的那張實體表上。一個 N/Y 翻來翻去的 flag,沒有東西可以掛約束,也保證不了「只成功一次」。N/Y 是個 binary,它表達不了 in-progress、失敗、可重排、已作廢;而我後面要做的條件式唯一索引、狀態機、ABORTED、reaper,全部建立在「工作項目有自己的多狀態欄位」這個前提上。沒有那張表,後面的東西通通玩不下去。
當然,要誠實補一句:獨立一張表不是萬靈丹。 如果這只是個一次性、無狀態、不用重試、重複了也無所謂的標記,一個 flag 就夠了,多開一張表反而是 over-engineering。是因為我們的這情境同時會有「多狀態 + 要重試 + 重複會賠錢」,那張工作表才划算。原作者是對的——但「對」是有前提的。
真的不要一開始沒看懂就在亂臭人家的設計耶XDDD
第一層:我以為加個鎖就好
來說說一開始為什麼會亂臭人家,先回到那個「兩邊同時做同一筆」的 race condition。
這是教科書等級的 read-then-write race:讀出狀態 → 根據狀態做事 → 寫回狀態,這三步之間沒有原子性,中間就會被插隊。我第一個念頭跟所有人一樣:「加個鎖不就好了,誰搶到誰先做。」
但這裡有個很容易忽略的盲點,我也是踩進去才看清楚:
批次那句「撈一千筆」的
SELECT,只是一份候選清單,不是佔有,別人還是可以拿走。
也就是說,批次在第 0 秒撈出一千筆要做的訂單,但系統要花好幾分鐘一筆一筆處理。在這幾分鐘裡,人工 API 完全可以插進來,把清單上某一筆的狀態改掉。批次手上那份清單,從撈出來的那一刻就開始過期了。
如果真的要在這層做點事,可以用 CAS(Compare-And-Swap):與其無條件處理,不如先用一句條件式 UPDATE 去「搶佔」——
-- 只有當它還是 WAIT 時,我才搶得到;搶到才繼續做
UPDATE schedule_item
SET status = 'PROCESSING' -- 佔住它(一個過渡用的「處理中」狀態)
WHERE run_id = :run_id
AND status = 'WAIT';
-- 看 affected rows:1 = 我搶到了,0 = 別人先搶走了,跳過
這能讓「逐筆佔用」這件事變原子,同時搶的機率下降。但我得先說:這還不是正確性的根本,只能算一層效率優化。 為什麼呢~?
第二層:鎖不是正確性的來源,冪等才是
這是整篇的轉折,也是我覺得最有價值的一段。
鎖(或 CAS)能做的事,是降低互搶的機率。但它擋不住兩件事:crash 跟 retry。
想像批次搶到了一筆、開始投產,做到一半程式掛了,或是網路斷了、下游一個 timeout 觸發了自動重試。鎖在這些情境下幫不了你——重試的那一次會帶著「我還沒做完」的認知再做一次,副作用(投產)就又發生了一次。對「重複=賠錢」的場景,光靠鎖不夠穩。
正確性必須落在一個更硬的地方:
讓「副作用本身」最多只發生一次。 不管你被呼叫幾次、retry 幾次、幾個流程同時進來,這張訂單就是只會被成功處理一次。這就是 冪等性(idempotency)。
怎麼保證?用一把從訂單本身獨特性定義出來的鑰匙(key),加上一個唯一約束。同一張訂單,不管是批次還是人工、不管被呼叫幾次,算出來的 key 都一樣;唯一約束會讓「再次成功」這件事在資料庫層直接 Fail。
鎖是效率,約束才是正確性。 鎖讓大家別撞在一起;約束保證就算撞了,同一筆也只會算一次。
於是我回頭檢視這張 schedule_item 表上的唯一約束。然後就想通了!!多麼聰明的設計!!!
第三層:破案——漏洞藏在 run_id 裡
這張表本來就有一個唯一約束,當初設計就是想用來擋重複的,才不是我說的為什麼要多拷貝一份出來害得自己要多 maintain 一份資料。
它大致長這樣(不要害我被 PIP),包含四個欄位:
UNIQUE (run_id, site_code, order_no, lot_no)
site_code / order_no / lot_no 是訂單的業務鍵,這三個合起來確實能唯一識別一張訂單。問題出在那個帶頭的 run_id——它是「哪一次批次執行」的 id。
而批次跟人工,是兩個不同的 run,run_id 自然不一樣。
於是悲劇發生了:同一張訂單(site_code / order_no / lot_no 三個都相同),因為一個來自 batch run、一個來自人工 run,run_id 不同,在資料庫眼裡就是兩筆完全不同的 row。唯一約束看著這兩筆,覺得「key 不一樣啊,沒重複」,開開心心讓它們都插進來。
唯一性被綁在「哪個 run 建的」上面,而不是綁在「這是哪張訂單」上面。
這就是那把鎖怎麼鎖都鎖不住的根因——不是鎖不夠強,是約束從一開始就放錯了維度。
修法很直覺:把 run_id 拿掉。 唯一性要綁在訂單身上:
UNIQUE (site_code, order_no, lot_no)
正當我想說,登愣!解了!結果開心不到三秒,下一個問題就來了。
第四層:但訂單會重排 → 條件式唯一索引
把 run_id 拿掉、改成三欄全域唯一之後,新的 run 一遇到同一筆訂單,就直接建不起來。因為——
FAILED 的訂單是要能重排的。
業務邏輯如下:一張訂單這次排程失敗(FAILED),下一輪應該要再被撈進來、重新排一次;但已經成功(SUCCESS)的訂單,永遠不能再排第二次。
如果我用三欄全域 unique,那 FAILED 過的訂單,下次想再進來時,它會跟自己上次那筆 FAILED 撞,直接插不進來。等於「失敗就再也不能重試」,這顯然不行。
所以我要的不是「全域唯一」,是有條件的唯一:只在「成功」或是「待排程」上保證唯一,放過「可以重排的狀態」。
- 會擋人(必須唯一):
WAIT、SUCCESS - 可重排(要放過):
FAILED、ABORTED
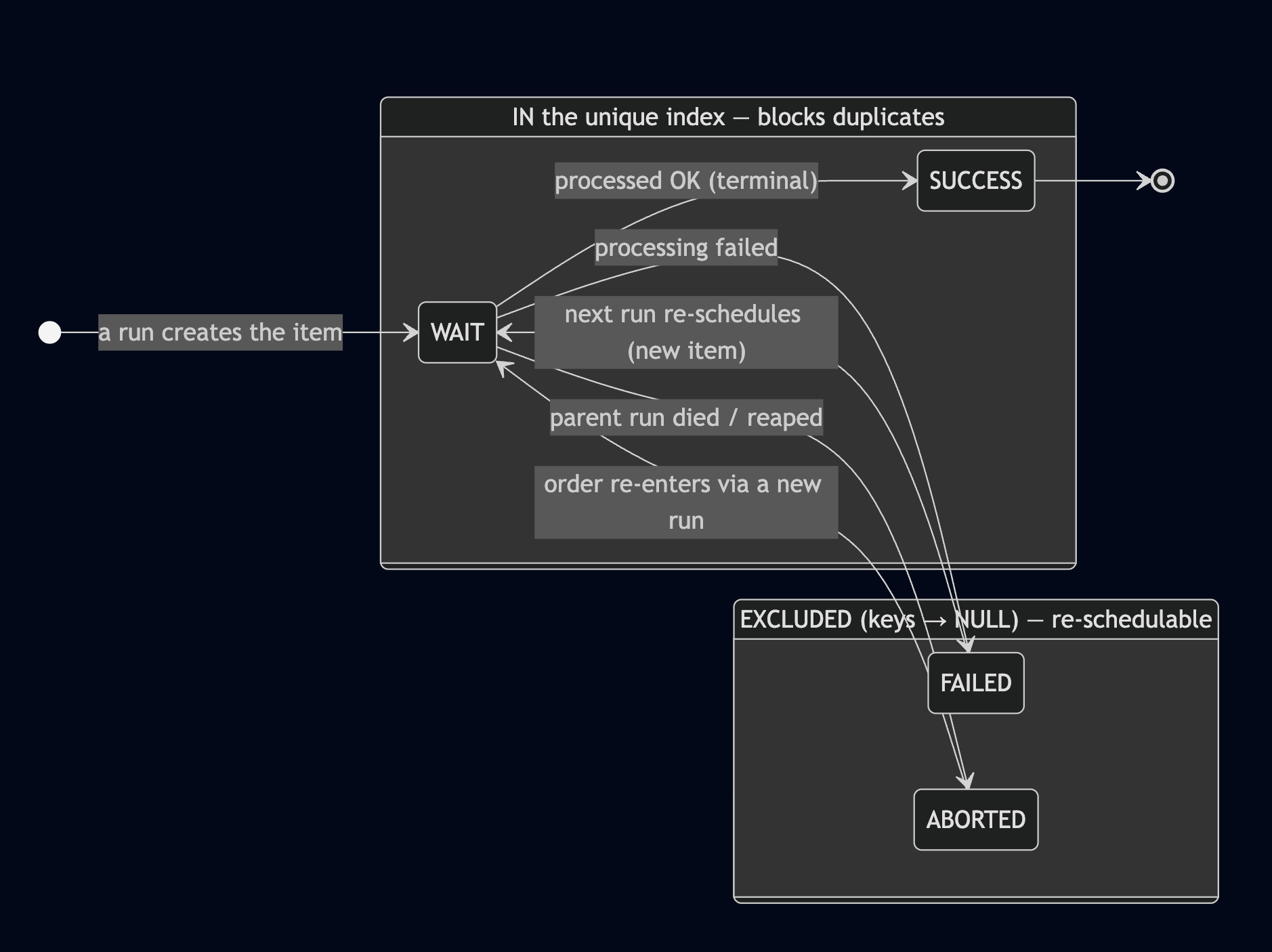
圖1. schedule_item 的狀態機:WAIT/SUCCESS 進唯一索引(擋重複),FAILED/ABORTED 三個 key 欄位被打成 NULL、排除在索引外(可重排)。
Oracle 沒有 PostgreSQL 那種 CREATE UNIQUE INDEX ... WHERE ... 的 partial index 語法,但有一個很漂亮的等效技巧:function-based 唯一索引 +「所有 key 欄位都是 NULL 的 row 不會進索引」這條規則。
也就是說,我用 CASE WHEN 把要排除的狀態,讓它的三個 key 欄位全部回傳 NULL。一旦三欄全 NULL,這筆 row 就不會被收進索引,自然也就不參與唯一性檢查:
CREATE UNIQUE INDEX ux_item_dedup ON schedule_item (
(CASE WHEN status NOT IN ('FAILED','ABORTED') THEN site_code END),
(CASE WHEN status NOT IN ('FAILED','ABORTED') THEN order_no END),
(CASE WHEN status NOT IN ('FAILED','ABORTED') THEN lot_no END)
);
FAILED / ABORTED 的 row,三欄都被 CASE 打成 NULL → 不入索引 → 可以無限重排;WAIT / SUCCESS 的 row 正常進索引 → 同一張訂單擋到死。
這裡還有一個我刻意的選擇:用黑名單 NOT IN ('FAILED','ABORTED'),而不是白名單 IN ('WAIT','SUCCESS')。原因是 fail-closed——將來如果有人新增一個狀態卻忘了更新這段邏輯,黑名單的預設行為是「把它當成會擋重複的狀態」,也就是往安全的方向倒(寧可擋錯,不可放過)。白名單剛好相反,新狀態預設會被放過、不參與唯一性,那是 fail-open,在「重複=賠錢」的場景是很危險的預設值。
到這裡,理論上問題解完了。然後我去資料庫實際下這道索引——撞了兩個坑。
踩坑實錄
坑一:ORA-02158: invalid CREATE INDEX option
我把上面那段 SQL 貼進 DBeaver 一跑,Oracle 回我 ORA-02158: invalid CREATE INDEX option。我盯著 SQL 看了很久,語法明明沒錯。
後來才發現:這不是 SQL 的錯,是客戶端工具的 parser bug。 DBeaver 在解析 function-based 索引裡那個「裸露的 CASE」時會解析錯誤,於是把鍋甩給 Oracle。
解法有兩個,挑一個就好:
- 每個
CASE再多包一層括號,讓 parser 不會誤判:(CASE ... END)(上面那段 SQL 我已經包好了,照貼就過)。 - 或者乾脆換個客戶端——用 SQL*Plus 或 SQL Developer 跑,根本不會有這個問題。
一個 parser bug 浪費我半小時,記錄下來給後人少踩一次。
坑二:ORA-01452: cannot CREATE UNIQUE INDEX; duplicate keys found
括號包好之後再跑,這次換 ORA-01452: ... duplicate keys found。這個就不是假警報了——它在告訴我:存量資料裡早就有重複。
也就是說,這個 bug 過去早就發生過,已經有重複的訂單躺在表裡了,只是一直沒人發現。先把它們揪出來:
SELECT site_code, order_no, lot_no, COUNT(*) cnt,
LISTAGG(status, ',') WITHIN GROUP (ORDER BY status) statuses
FROM schedule_item
WHERE status NOT IN ('FAILED','ABORTED')
GROUP BY site_code, order_no, lot_no
HAVING COUNT(*) > 1;
找到之後,重點是:解法不是 DELETE。 直接刪資料太粗暴,也丟了稽核軌跡。我要的是「軟轉移」——每組重複只留一筆「正主」,其餘的翻成 ABORTED(作廢、但留著)。
留哪一筆有規則:如果該組裡有 SUCCESS,就留 SUCCESS(既成事實不能動);否則留最新的那筆 WAIT。一句 UPDATE 加 ROW_NUMBER() 就搞定:
UPDATE schedule_item SET status = 'ABORTED'
WHERE ROWID IN (
SELECT rid FROM (
SELECT ROWID rid,
ROW_NUMBER() OVER (
PARTITION BY site_code, order_no, lot_no
ORDER BY CASE status WHEN 'SUCCESS' THEN 0 ELSE 1 END,
created_at DESC
) rn
FROM schedule_item
WHERE status NOT IN ('FAILED','ABORTED')
)
WHERE rn > 1
);
ORDER BY 那段是關鍵:先讓 SUCCESS 排到最前(THEN 0),再用 created_at DESC 讓最新的排前面;ROW_NUMBER 給每組編號,rn = 1 是要留的正主,rn > 1 全部作廢。清乾淨之後,索引就建得起來了。
不想動存量的替代法:ENABLE NOVALIDATE
如果情境不允許你動既有資料(例如稽核要求、或量太大不敢碰),還有一條路:用 virtual column + 非唯一索引 + 唯一約束 ENABLE NOVALIDATE。
NOVALIDATE 的意思是「從現在起往前保護新進資料,但不回頭驗證存量」。等於把存量裡的真重複「就地特赦」,只擋未來。代價很明確:那些既有的真重複,本身不受保護。 要不要用,取決於你能不能接受「過去的帳就這樣了」。我自己是選了上面那條軟轉移,因為我想連存量一起乾淨。
第五層:WAIT 在說謊——其實是狀態機的洞
索引建好了,存量也清乾淨了,我以為這事結束了。結果隔天,新的 run 又建不起來。
報錯一樣是撞唯一索引。我查了半天,發現兇手是一批卡在 WAIT 的工作項目——它們的 parent run 早就死了,但它們自己還停在 WAIT,於是還待在索引裡,擋住了新 run 想為同一張訂單建立的新項目。
根因浮出水面,而它跟開頭那個 SSOT 的病,是一模一樣的:
WAIT這個狀態,被當成了兩種意思:
- 「我屬於一個活著的 run,正排隊等處理」(真的待處理)
- 「我的 parent run 已經死了,我是一具孤兒」(其實早該作廢)
一個欄位背了兩種語意。而索引只看得到自己那張表——它不會、也不該去 JOIN parent run 來判斷你是不是孤兒。所以狀態欄位本身就必須說實話。
要守的不變量(invariant)一句話講完:
一筆
WAIT,一定對應到一個存活的 parent run。
這裡先把存活定義清楚。一個 run 自己也有狀態:CREATING / RUNNING 是存活(還在跑),DONE / ERROR 是終態(已結束)。所謂「孤兒 WAIT」,就是 parent run 已經進了 DONE 或 ERROR,自己卻還停在 WAIT 的項目。
要維持這個不變量,我做了三件事,外加一件選配:
(1) run 轉 ERROR 時,連坐它底下的 WAIT。 當一個 run 進入終態 ERROR,就把它底下還停在 WAIT 的項目一起轉成 ABORTED——run 都死了,它的待辦不該還掛在那擋人。
(2) reaper 定期掃孤兒。 加一支排程,定時把「parent 已死、或卡太久」的孤兒 WAIT 收成 ABORTED,當作 (1) 漏網的安全網:
UPDATE schedule_item si SET status = 'ABORTED'
WHERE si.status = 'WAIT'
AND NOT EXISTS (
SELECT 1 FROM schedule_run r
WHERE r.run_id = si.run_id
AND r.status IN ('CREATING','RUNNING') -- 只有這兩個算「存活」
);
(3) 把不變量寫成監控查詢。 最理想的狀態是這句查詢永遠回 0 筆;一旦 > 0,代表不變量被破壞了,該告警:
SELECT si.* FROM schedule_item si
JOIN schedule_run r ON r.run_id = si.run_id
WHERE si.status = 'WAIT'
AND r.status NOT IN ('CREATING','RUNNING'); -- WAIT 卻掛在死掉的 run 底下
(4)(選配)建立時順手清理。 新 run 在 insert 前,先把「沒有存活 parent」的孤兒 WAIT 收掉。但這裡有一個絕對不能犯的錯:
千萬不能無差別地把「所有
WAIT」都清掉。
因為此刻可能正有另一個活著的 run 底下也躺著一堆 WAIT,那是它正要做的單。你一個無差別清理,會把別人正在做的訂單殺掉,直接造成漏單——而漏單在製造業同樣是賠錢。清理一定要帶上「parent 已死」這個條件,一筆都不能多殺。
最後說明兩個設計決定:
- 為什麼新增一個獨立的
ABORTED,而不是重用FAILED? 因為語意不同。FAILED是「這次排程嘗試失敗了,之後該重排」;ABORTED是「這筆作廢了,不該再被碰」。如果我把孤兒塞回FAILED,它們會被下一輪當成「待重排」又撈進來,問題原地復發。語意不同,就該有自己誠實的狀態,這又回到那條主線了。 - 一條鐵則:任何「可重排」的新狀態,都必須同步加進索引的排除清單。
ABORTED是可重排語意(不擋人),所以它必須在NOT IN ('FAILED','ABORTED')裡。漏掉這步,作廢的項目會繼續佔著索引擋新單。狀態機跟索引是綁在一起演化的,改一個就要想到另一個。
而這整件事最深的一課是:我修的根本不是索引,是狀態機。 索引只是那個忠實的告密者,它把一個潛伏很久、誰都沒注意到的資料模型 bug,硬逼上了檯面。
總結:我一開始問錯了問題
回頭看這整趟,幾個我想留下來的東西:
- 正確性該住在 DB 約束裡,不是 app 的鎖裡。 鎖降低撞車機率,是效率層;唯一約束保證副作用只算一次,是正確性層。兩者別搞混,更別用鎖去假裝有正確性。
- 唯一索引是最誠實的告密者。 它把一個藏在資料模型裡、潛伏很久的 bug 逼了出來。很多「偶發、查不到、重現不了」的怪事,根因都在約束放錯維度。
- 把關鍵不變量寫成一句可執行的 SQL,當監控。 「一筆
WAIT一定有存活的 parent」這種不變量,與其放在文件裡長灰塵,不如變成一句「理想恆為 0」的查詢掛上告警。會說話的約束,比寫得再漂亮的註解都可靠。 - 維護要有紀律。 狀態機跟索引排除清單是綁死的,加新狀態就要同步想到索引;黑名單 fail-closed,永遠往安全的方向倒。
但其實最大的收穫,跟技術沒什麼關係。
我這趟從頭到尾,都在反覆驗證同一條原則:每個事實、每個狀態,都該有自己誠實的家,別讓一個欄位或一張表背多重語意。 開頭我嫌「為訂單多開一張表」多餘,結尾我抓到「
WAIT一詞兩義」的洞——是同一個病的一頭一尾。
我一開始帶著「原作者是不是在找麻煩」的心態進場。整趟 debug,其實是我慢慢看懂這個設計為什麼要這樣蓋。最大的收穫是:我發現自己一開始就問錯了問題。 我問的是「為什麼不合併成一張表」,但對的問題從來都是「這個事實的家,應該在哪裡」。
技術會過時,但「先搞懂再批評」這件事不會。還好有 Claude 這個寫 code 諮詢師,教會我這件事。
Reference
- Oracle Database — Function-Based Indexes(NULL key 不入索引的行為)
- Oracle Database —
ENABLE NOVALIDATE約束狀態 - Idempotency 與 deterministic key 設計:在「重複=副作用」的系統裡用唯一約束保證 exactly-once 的常見手法